Memory 성능 분석
쿼리는 데이터를 처리 전에 메모리에 먼저 먼저 올려놓고 작업하게 된다. 조회뿐 아니라 데이터 수정하는 경우에도 데이터를 먼저 메모리에 적재 후 수정하고 디스크로 내려보낸다. 이렇게 대부분의 데이터 연산 작업들은 메모리를 통해서 이뤄지기 때문에 충분한 이해가 필요하다.
이번장에서 다룰 주제
- 성능 모니터의 기본
- 몇몇 시스템 활동상황을 관찰하기 위해 사용되어지는 동적 관리 오브젝트
- 어떻게, 왜 하드웨어 리소스는 병목을 발생시키는지
- SQL Server 와 윈도우 OS에서 사용되어지는 메모리를 관찰하고 측정하는 방법
- 메모리 병목의 가능한 해결책
내가 이번 장에서 추가한 내용이 50% 정도 될 듯하고 원본 내용은 50%도 안된다. 아무래도 원래 책은 매우 높은 수준의 전문가를 대상으로 쓰여져서 기본 개념에 대해서는 설명하지 않는다.
하지만 내가 이 문서를 작성할 시기에 교육 대상은 그 정도는 아니었기 때문에 기본 개념이나 추가한 것들이 많게 되었다.
SQL Server의 메모리를 조사하기 전에 먼저 OS 메모리 할당을 먼저 알면 매우 도움이 된다.
아쉽게도 Windows OS와 SQL Server는 동음이의어가 많아 매우 헷갈린다. 그렇기 때문에 어느 쪽 용어인지 확실히 이해해야 한다. OS쪽 메모리 먼저 정리하고 SQL Server 로 넘어가면 매우 큰 도움이 되며 이 문서에도 용어의 틀린점과 양쪽 메모리의 할당과 서로 연관된 구조를 차례대로 설명하겠다.
먼저 우리 SQL Server는 64비트 머신이지만 32bit가 설명이 쉬우니 32bit라고 가정하자.
일반적인 프로그램이 실행되어 프로세스라고 불리우게 되면 유저모드 2GB, 커널모드 2GB, 총 4GB 메모리를 사용할 수 있다. 하지만 물리적인 메모리 용량은 한정되어 있으니 실제 할당은 하지 않고 마음속에만 4GB의 가상의 공간을 미리 생각하고 있는것이다. 실제 메모리의 공간이 필요하게 될때만 페이지(4KB) 단위로 실제 메모리를 할당 받는다. 여기서 첫번째 용어 차이인 페이지가 등장한다. SQL Server의 페이지와는 용어는 같지만 다른 개념이니 주의. SQL Server의 페이지는 8KB단위이며 메모리의 페이지는 4KB단위(x86, x64).
물리적인 메모리를 4KB 페이지 단위로 할당 받으면 이때를 commit 이라고 한다. 정확히는 내 마음속의 가상 주소와 실제 메모리 주소를 매핑하는것. 그리고 또 SQL Server의 commit과 동음이의어니까 조심. 작업 관리자 등에서 commit이라고 나오는 것은 다 메모리상에 할당 받는 것을 말하고 SQL Server의 트랜잭션 commit과는 상관없다.
C언어를 할 줄 알면 VirtualAlloc으로 메모리 예약, 할당 받고 VirtualFree로 물리적 메모리를 해제하는데 익숙할 것이다.
또 하나 알아두어야 할것은 프로그램의 물리적 메모리 뿐만 아니라 가상메모리(페이징 파일:pagefile.sys)도 사용할 수 있다는 것이다. SQL Server도 시작할때 마음속의 가상공간(64비트일때 64Ebyte)을 할당받는데 물리적 메모리 + 가상메모리 를 합친 공간이다.
SQL Server에 익숙하시다면 Lock pages in Memory 라는 옵션에 익숙할 것이다.
무슨 뜻이냐면 SQL Server도 OS위에서 작동하는 프로그램이기 때문에 물리적 메모리의 공간이 부족하면 가상메모리쪽으로 데이터 스왑을 하게 되는데 이때 엄청난 속도 저하가 발생한다. 대부분의 SQL Server는 대용량의 메모리를 가지고 있고 자체적으로 lazy writer와 같은 기능을 가지고 있기 때문에 엄청나게 느린 페이징 스왑 작업을 못하게 해야 한다. 그래서 pages 들을 스왑하지 못하게 memory안에 데이터를 Lock 하는것이다. 여기서 페이지는 메모리의 페이지이다. 밑에서 DBCC MemoryStatus 에서 좀더 자세히 설명한다.
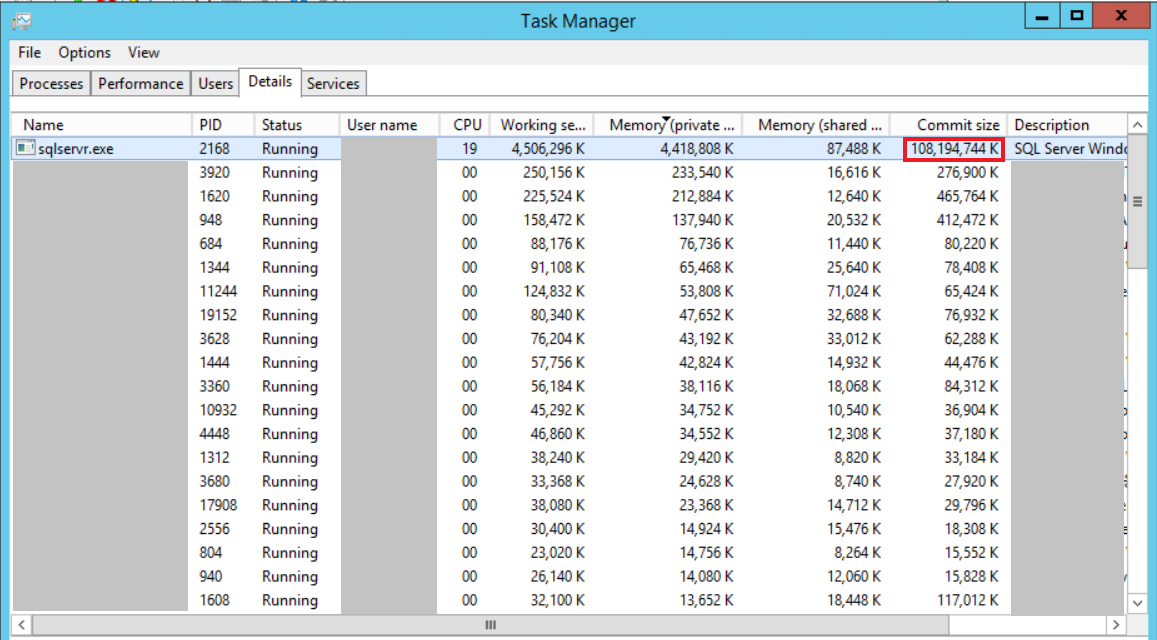
작업 관리자의 Commit Size라는 열에서 실제 SQL Server가 차지하고 있는 메모리 용량을 볼수 있다. 여기의 commit 도 메모리의 용어.
제목 열을 오른쪽 클릭하면 select column 이 나오고 commit size 항목도 추가해야 볼수 있음
2.1 성능 모니터
성능 모니터는 CPU, Memory, Disk, Network의 자세한 활동 데이터를 측정하는 Windows OS의 기본 도구이다. 또한 SQL Server 2014에서는 추가적인 기능을 성능 모니터를 통해 사용 가능하기도 한다.
단 VM에서 측정하는 값은 논리적인 VM 각각의 데이터이기 때문에 물리적 서버의 데이터가 아니다. 정확한 데이터가 아니기 때문에 주의.
시스템 실시간 활동데이터를 그래프로 바로 볼 수도 있고, data collector set 이라는 파일로 저장할 수도 있다.
실서버에서는 파일로 저장하는게 오버헤드가 더 적기 때문에 보다 선호하는 방법.
명령도구(cmd.exe)에서 perfmon 이라고 치면 성능 모니터가 실행됨.
2.2 동적 관리 오브젝트
내부적으로 동적관리오브젝트(DMO)를 사용하는 동적관리뷰(DMV)와 동적 관리함수(DMF)라는 형태로 SQL Server에서도 성능모니터의 실시간 스냅샷 데이터를 제공한다.
sys.dm_os_performance_counters dmv는 쿼리로 SQL Server의 카운터를 쿼리로 볼수 있게 해준다. 아래는 Login/sec 예제
SELECT cntr_value
, cntr_type
FROM sys.dm_os_performance_counters
WHERE object_name = 'SQLServer:General Statistics'
AND counter_name = 'Logins/sec';
이때 cntr_value 는 현재까지 누적치이고 cntr_type은 각각의 카운터를 가르키는 정수값이다. 여기 서 참조 가능
sys.dm_os_wait_stats 는 다양한 대기 상태의 누적치. 대기상태를 아는 것은 병목의 원인을 알수있는 가장 쉬운 방법이다.
SELECT TOP (10) dows.*
FROM sys.dm_os_wait_stats AS dows
ORDER BY dows.wait_time_ms DESC;
Microsoft에서 대기상태 찾기.
2.3 하드웨어 리소스 병목
일반적으로 다음 4개의 하드웨어 리소스를 살펴보고 병목을 알수 있다.
- 메모리
- Disk I/O
- CPU
- Network
병목 알아내기
하드웨어 리소스간의 병목에는 서로 밀접한 관계가 있다. 예를 들면 CPU병목은 과도한 페이징(메모리 병목)이나 디스크 속도 저하(디스크병목)같은 증상도 동시에 유발한다. 또한 시스템 메모리가 부족할때도 과도한 페이징이 디스크에 엄청난 압박을 가한다. 이때 CPU를 더 빠른 것으로 교체하는것은 약간의 좋은 해결책이 될수 있겠지만 최적의 방법은 아니다. 메모리 증설이 디스크/CPU의 압박을 줄여주기 때문에 좀더 적절한 해결방법이다.
병목 식별 방법
- 가장좋은 방법 : 처리를 완료하기 위해 한 리소스가 다른 리소스를 기다리는지 알아내는 법
- 두번째 방법 : 응답시간과 용량을 조사해 알아내기
예를 들면 벤더가 제시한 대역폭과 용량을 알기. 그 이상을 넘으면 과도한 로드라고 할수 있다.
모든 하드웨어 리소스가 쿼리로 조회 가능한 성능 카운터들을 가지고 있는건 아니지만 사용을 표시하는 카운터는 대부분의 리소스에 존재.
예) 메모리는 그러한 카운터는 없지만 큰 숫자의 하드 페이지 폴트는 물리적 메모리의 한계가 부족하다는 것을 의미. (pages/sec, page faults/sec)
CPU나 디스크과 같은 다른 리소스들도 대부분 queue 수치 카운터가 존재한다.
병목 해결 방법
일단 병목을 발견하면 다음 두가지 방법중 하나를 선택할 수 있다.
- 하드웨어 리소스를 증설
- 리소스를 사용하는 방법을 교정(쿼리 튜닝과 같은)
2.4 메모리 병목 분석
메모리 병목 현상은 시스템의 다른 리소스에도 문제를 발생.
예) SQL Server가 버퍼 캐시가 부족하게 되면
- SQL Server의 프로세스(lazy writer같은)는 충분한 여유 내부 메모리페이지를 유지하기 위하여 과도하게 작동한다.
- 이는 과도한 CPU 사용률
- 메모리 페이지를 디스크에 쓰려하는 추가적인 물리적 disk I/O를 발생
- SQL Server 메모리 관리 SQL Server의 메모리 구성 - 데이터베이스용 메모리 - 데이터용 메모리 요구사항 - 쿼리 실행계획 - 버퍼풀이라고 불리는 대량의 메모리 풀
메모리 풀은 8KB 버퍼들의 컬렉션. 데이터 페이지, 플랜 캐시 페이지, 프리 페이지와 같은 다양한 페이지 존재 SQL server는 동적으로 메모리 풀 크기를 늘리거나 줄임.
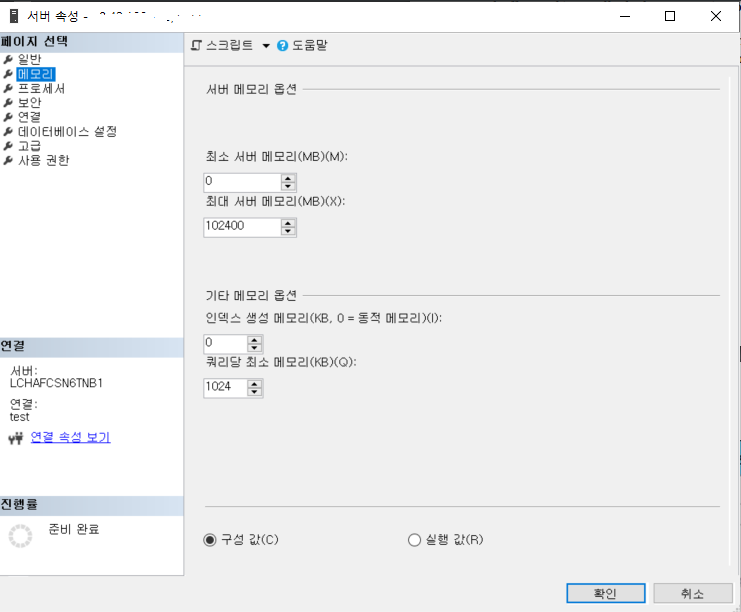
SSMS에서 세팅방법 서버등록정보/메모리
동적 메모리 범위 두개의 구성 정보.
* Minimum(MB) : "min server memory". 메모리 풀의 희망하는 가장 낮은 값. 일단 메모리 풀이 최소값과 같은 크기에 도달하면
SQL Server는 메모리 풀의 페이지를 계속 커밋 할 수 있지만 최소값보다 작게는 축소 할수 없다.
* Maximum(MB) : "max sserver memory". 메모리 풀의 희망하는 최대 값 . 이러한 구성 설정은 즉시 적용되며 다시 시작할 필요가 없습니다.
보통 Min 값은 디폴트로 놓고 max값만 조절한다.
- 예
a. OS 메모리 용량이 128GB일때 Min 을 1GB 로 잡고 Max를 110GB로 잡는다면
b. 처음 SQL Server가 기동되면 매우 적은 몇MB상태일 것이다.
c. 사용이 늘게되면 점점 메모리 사용이 늘게 될것이고 어느 순간 1GB를 넘는다
d. 점점 사용이 늘다가 최대값인 110GB까지 사용하게 되는 날도 있다.
e. 최대 110GB 는 넘지 않다가 서비스가 망해서 SQL Server도 점점 사용량이 준다.
f. 하지만 1GB 가 min이기 때문에 그 이하로는 떨어지지 않는다
Microsoft는 동적 메모리 권장을 사용하도록 권장.
* min server memory는 0.
* Max server memory는 OS에 약간의 memory 허용치를 놔두게.
8~16GB 메모리 일 경우 OS메모리는 2~4GB 여유. 일반적으로는 5GB ~ 10GB 정도 빼준다.
최소 서버 메모리가 0 인 SQL Server에 동적 메모리 구성을 사용하는 것이 좋습니다.
최대 서버 메모리는 시스템의 단일 인스턴스를 가정하여 운영 체제에 일부 메모리를 허용하도록 설정됩니다.
운영 체제의 메모리 양은 시스템 자체에 따라 다릅니다. 메모리의 경우 약 2GB-4GB를 OS에 남겨 두어야합니다. 서버의 메모리 양이 증가함에 따라 OS에 더 많은 메모리를 할당합니다.
SQL Server 의 메모리는 크게 데이터페이지와 프리페이지가 있는 버퍼풀 메모리와 쓰레드, DLL들, 연결된 서버들 등등이 있는 비버퍼 메모리로 나눠진다. 대부분은 버퍼풀이 차지. 그러나 버퍼풀 그 너머 영역(private bytes라고 알려진)까지 얻을 수 있긴 하지만 일반적으로 버퍼풀 모니터링하는 정상적인 절차에 걸리지 않기 때문에 메모리 압박을 유발 할수도 있다. 이런 상황이 의심스럽다면 Process:sqlserver:Private Bytes 와 SQL Server: Memory Manager: Total Server Memory 를 비교해보자
sp_configure 를 이용해 min server memory와 max server memory를 설정할 수 있다.
EXEC sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
EXEC sp_configure 'min server memory';
EXEC sp_configure 'max server memory';
| name | minimum | maximum | config_value | run_value |
|---|---|---|---|---|
| min server memory (MB) | 0 | 2147483647 | 0 | 16 |
| name | minimum | maximum | config_value | run_value |
|---|---|---|---|---|
| max server memory (MB) | 128 | 2147483647 | 102400 | 102400 |
min server memory의 값이 0MB 이고 max server memory가 2147483647MB인것에 주의
max server memory를 10GB, min server memory를 5GB 로 세팅하는 예제
USE master;
EXEC sp_configure 'show advanced option', 1;
RECONFIGURE;
exec sp_configure 'min server memory (MB)', 5120;
exec sp_configure 'max server memory (MB)', 10240;
RECONFIGURE WITH OVERRIDE;
show_advanced option을 1로 킨 다음에 세팅해야 정상적으로 완료됨. sys.configuration 뷰를 통해서도 메모리 세팅 값을 조회할수 디다.
* 메모리를 분석할수 있는 성능 모니터 카운터
| 오브젝트 | Counter | 설명 | 값 |
|---|---|---|---|
| Memory | Availble Bytes | 물리적 메모리의 여유 용량 | 102400 |
| Pages/sec | 초당 하드 페이지 폴트 수 | 보통 평균 < 50. 베이스라인 참고 | |
| Page Faults/sec | 총 페이지 폴트(소프트 + 하드) | 베이스라인 참고 | |
| Page Input/sec | input page faults(디스크에서 읽기) | ||
| Page Output/sec | output page faults(디스크에 쓰기) | ||
| Paging File | Paging File %Usage Peak | 메모리 페이징 파일 사용률 최대 수치 | |
| Paging File: %Usage | 메모리 페이징 파일 사용률 | ||
| SQLServer:Buffer Manager | Buffer cache hit ratio | 버퍼 캐시의 데이터를 쓰는 비율 | |
| Page Life Expectancy | 버퍼캐시에 머무루는 시간(초) | 베이스라인 비교 | |
| Checkpoint Pages/sec | 체크포인트로 초당 디스크 쓰기 페이지수 | 평균 < 30. 단 베이스라인과 비교필요 | |
| Lazy writes/sec | 버퍼에서 날라간 더티 페이지수 | 평균 < 20. 단 베이스라인과 비교필요 | |
| SQLServer:Memory Manager | Memory Grants Pending | 메모리 그랜트를 기다리는 프로세스 수 | 평균 0 |
| Target Server Memory (KB) | SQL Server 가질수있는 최대 물리메모리 용량 | 물리적 메모리 크기에 근접해야 | |
| Total Server Memory (KB) | SQL Server의 현재 물리 메모리 용량 | Target Server Memory (KB)에 근접해야 | |
| Process | Private Bytes | 다른 프로세스와 공유하지 않는 이 프로세스만의 메모리 사이즈 |
메모리와 디스크 I/O 간에는 밀접한 관계가 있다. 메모리 문제라고 생각했던게 사실 디스크 I/O때문 일수도 있음.
* Available Bytes
OS 메모리의 여유 용량. "Available Kbyte", "Available MByte" 도 사용가능. 이 카운터 수치가 너무 낮으면 안됨.
SQL Server가 동적 메모리 관리를 사용하도록 구성되어 있다면 이 값은 Windows API에 의해 조절된다.
* Pages/Sec, Page Faults/Sec
페이지 폴트 : 프로그램(윈도우 프로세스)이 필요한 데이터가 자기만의 물리적 메모리상의 공간인 Working Set에 없을 경우 발생.
- 소프트 페이지 폴트 : 필요한 데이터가 물리적 메모리의 다른 공간에 있어서 거기서 찾을 수 있으면
- 하드 페이지 폴트 : 데이터를 하드 디스크에서 찾아야 하는 경우
하드 페이지 폴트의 성능 향상을 위해 SSD를 쓰긴 하지만 그래도 밀리세컨트 단위인데 메모리는 나노세컨드, 비교 불가
- Pages/sec : 하드페이지 폴트를 해결하기 위해 디스크에 읽고 쓰는 초당 페이지 수이다. (x86,x64에서 페이지는 4KB 단위).
- Page Faults/sec : 소프트 페이지 폴트 + 하드 페이지 폴트 = 전체 폴트 초당 총 페이지 수.
총 페이지 폴트는 데이터 로드의 주된 요소이고 성능 이슈의 직접적인 지표는 아니다.
Pages/sec으로 표시되는 "하드 페이지 폴트"는 꾸준하게 보통보다 낮아야 한다. 디스크와 메모리의 종류, 속도, 용량 등등 시스템의 다양한 변수가 있기 때문에 얼마가 보통이고 얼마가 문제인지 판단 할수 있는 절대적인 기준 수치는 없다.
Pages/sec 수치가 높다면 "Pages Input/sec"과 "Pages Output/sec" 으로 나눠 좀 더 세부적으로 조사해야 한다.
- Pages Input/sec : 디스크에서 읽기. input page 동안만 어플리케이션이 대기.
- Pages Output/sec : 디스크에 쓰기. 항상 부하가 되는 건 아니고 Page output은 보통 어플리케이션 더티 페이지(디스크에 다시 쓰여지는)로 표현.
디스크 로딩 이슈가 발생할 때만 문제의 원인이 된다.
Process:Pages Faults/sec 을 통해 어떤 프로세스가 높은 Pages/sec의 원인인지 최종 범인을 확정. Process 오브젝트는 프로세스 별로 성능 데이터 수치 측정. SQL Server의 기본 프로세스 명은 "sqlservr". Memory:Pages/sec 수치가 높지 않다면 Process(sqlservr):Pages Faults/sec 은 높아도 크게 의미있지 않다. 소프트페이지 폴트만 발생하는 것이기 때문에.
Pages/sec은 일반적으로 0에서 10000 까지 볼수 있기 때문에 매우 넓은 범위에 걸쳐 있다. 그렇기 때문에 보통상태의 수치가 얼마인지 베이스라인 측정 작업을 평소에 해 놓아야 한다.
정리하자면
- os 단위
>> page fault (Pages Faults/sec) --- soft page fault
>> |
>> --- hard page fault(pages/sec) --- Pages Input/sec
>> |
>> --- Pages Output/sec
- process 단위
>> Process(sqlservr) -- Pages Faults/sec
프로세스 단위에는 Pages Input/sec, Pages Output/sec 카운터가 없다.
* Paging File %Usage, Page File %Usage
윈도우의 모든 메모리는 물리적 메모리만이 아니다. 가상메모리(페이징파일)도 존재하는데 필요할때 물리적 메모리와 데이터를 스왑한다. 이 카운터로 얼마나 자주 스와핑이 발생하는지 이해할 수 있다. 보통은 SQL Server가 아니고 Windows OS에서 수행된다. 하지만 충분하지 않은 가상메모리는 SQL Server까지 영향을 미친다. 이 수치는 SQL Server상의 메모리 압박이 내부적 또는 외부적인지 이해하기 위해 수집된다. 외부의 메모리 압박이라면 SQL Server 이외의 어떤 요소가 문제인지 OS 단에서 확인할 필요가 있다.
* Buffer Cache Hit Ratio
버퍼 캐시는 메모리상에서 존재하는 데이터의 버퍼 풀이다.
종종 SQL Server 메모리 구조에서 가장 큰 부분을 차지하며 이 카운터는 OLTP 시스템에서는 가능한 높아야 한다. 대부분의 프로덕션 서버에서는 99%. 낮은 Buffer Cache Hit Ratio은 필요한 데이터가 버퍼 캐시 밖(하드디스크)에 존재함을 의미. 낮은 경우는 SQL Server에 처음에 워밍업할, 메모리 부족일 경우만 발생
버퍼 캐시 적중률이 계속 낮은 수치일 경우 - 물리적 메모리 증설 - 적절한 인덱스 추가 or 쿼리 튜닝
만약 리포팅 시스템, DW같은 OLAP성 작업이라면 쿼리 하나하나가 매우 대량의 데이터를 메모리에 올리고 사라지고 하는게 일반적이기 때문에 이 때문에 낮은 수치를 보여지는게 정상. 또한 얼마만큼의 권장 수치 존재치 않지만 대부분 OLTP는 99% 근처.
* Page Life Expectancy(PLE)
메모리가 부족한지 아닌지 판단해야 하는 경우 가장 먼저 Page Life Expectancy.
SQL Server 데이터 페이지(8K)를 메모리에 적재한 후 삭제되지 않는 평균 시간(초 단위). 이 수치가 놎은 경우 OLTP 시스템에서 유리. 이 수치가 낮다면 메모리 압박 상태. 버퍼캐시에 필요한 데이터가 존재한다면 시간이 오래걸리는 디스크 조회 작업을 안할수 있기 때문에 PLE 수치는 계속 오르게 된다.
OLAP성 작업(DW, 마트, 리포팅 서버 등등)은 대량 데이터를 끊임없이 디스크에서 메모리로 퍼올리기 때문에 보통 이 값이 낮다.
권장하는 절대적 수치는 없다. 하지만 과거 MS에서 300초(5분)이상 되어야 한다고 권고했었던 적이 있는데 그게 20년전이었고 일부 MS문서에도 아직 300으로 남아 있다. 그렇기에 최근까지도 300이 절대적인 수치라고 알고 있는 사람이 많다.
결론부터 말하지만 현재 300은 너무 작은 값이다. 최근 몇 년간 하드웨어/메모리의 사양이 급격하게 증가했기 때문에 현실적인 조정된 새 기준이 필요하다. 외국 유명 SQL Server 엔지니어는 1200(20분) 이라는 사람도 있던데 개인적으로 정답은 아니지만 근접한 답은 된다고 생각된다. 베이스라인 작성과 Lazy Write/sec 수치와 같이 고려해야 최종 판단 필요. NUMA도 잘 지원하는데 다음과 같다.
- 해당 SQL Server의 인스턴스의 PLE가 알고 싶다면
Buffer Manager: Page Life Expecany
- 각 NUMA 노트의 PLE 알고 싶다면
Buffer Node: Page Life Expecany
* Checkpoint Pages/Sec
SQL Server 엔진은 성능상의 이유로 변경 내용이 있을 때마다 메모리(버퍼캐시)에서 데이터 페이지를 수정하며 이러한 페이지를 바로 디스크에 기록하지는 않는다. 메모리상에서만 변경되고 디스크에 기록되기 전의 데이터베이스 페이지를 "더티 페이지".
Checkpoint Pages/Sec 카운터는 체크포인트로 인해 메모리에서 디스크로 이동하는 더티 페이지들의 초당 숫자.
대부분의 경우 30보다 낮아야 한다. 이보다 높은 수치는 메모리 버퍼에 더티 페이지로 표시된 페이지들이 많다는 것을 의미한다.
이 수치가 높으면 시스템에 쓰기 작업이 많고 I/O 문제 발생할 가능성 많음.
SELECT *
FROM sys.configurations
where name like 'recovery interval%'
GO
/*
configuration_id name value minimum maximum value_in_use description is_dynamic is_advanced
---------------- ----------------------- ----- ------- ------- ------------ ------------------------------------ ---------- -----------
101 recovery interval (min) 0 0 32767 0 Maximum recovery interval in minutes 1 1
*/
"recovery intervals" SQL 서버 범위의 체크포인트 주기를 결정하는 값이다.
기본값은 0이고 60초 단위로 체크포인트를 수행한다는 뜻이다. 이 때를 "자동 체크포인트"라고 부른다.
SQL Server 2012부터는 "간접 체크포인트" 라고 부르는 데이터베이스 단위로 체크포인트 주기 결정 기능이 추가되었다.
SELECT database_id, name AS DBName, target_recovery_time_in_seconds
FROM sys.databases
WHERE name = 'AdventureTime'
GO
/*
database_id DBName target_recovery_time_in_seconds
----------- ---------------- -------------------------------
6 AdventureTime 0
*/
"target_recovery_in_seconds" 값으로 데이터베이스 단위로 체크포인트 주기를 결정할 수 있게 된다. 기본값은 0이고 이 때는 서버 구성을 따른다는 의미. 만약 이 값이 0이 아니라면 서버 설정은 무시하고 데이터베이스 쪽 설정이 우선된다.
2016버전부터는 데이터베이스 설정이 우선이고 기본값은 60초이다. 단 지금 예제 서버는 2014 버전이기 때문에 0으로 표시돤다.
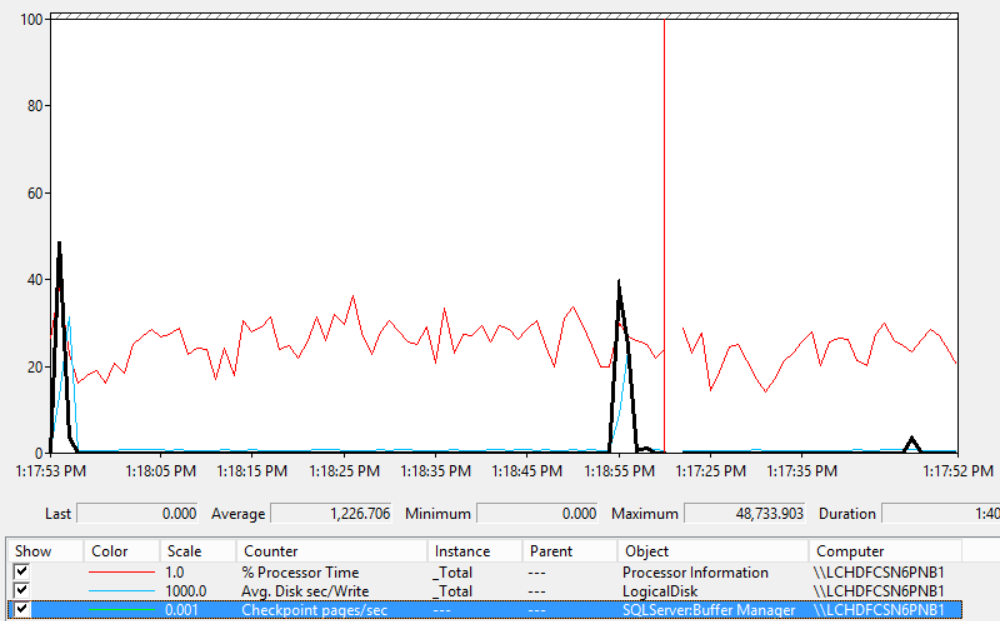
수치를 보면 알 수 있듯이 이 SQL Server는 쓰기 작업이 매우 많은 서버이다.
여기서 SQL 서버의 "recovery interval" 도 0이고 Database의 target_recovery_time_in_seconds 값도 0이니 서버쪽 옵션을 따라 60초마다 체크포인트가 발생하는 것을 알 수 있다.
"Checkpoint Pages/Sec" 가 30을 넘기 때문에 메모리상의 더티 페이지가 많이 발생하고 메모리와 디스크I/O의 성능 이슈가 발생할 가능성이 높다.
잘 안보이지만 파란색 선이 디스크의 평균 write 카운터이다. 정확히 1분마다 체크포인트 발생과 동시에 I/O가 치솟는 것을 알 수 있다.
1분마다 발생하는 과도한 I/O를 60초에 나누어 고르게 분산되도록 조정해야 한다. target_recovery_in_seconds값을 60보다 차츰 줄여 가면서 I/O가 고르게 분포하게 되는 수치를 정하는게 목적이다.
참고
Database checkpoints – Enhancements in SQL Server 2016
* Lazy Writes/sec
Lazy Writer 프로세스에 대해 먼저 알아야 한다.
SQL Server는 쿼리 작업전에 메모리 버퍼 캐시의 빈공간(free page)를 확보해야 하는데 여유 공간이 부족하게 되면 버퍼 캐시에서 오래된 데이터 페이지들을 삭제하여 공간을 확보하게 된다. 이 때 클린 페이지과 더티 페이지가 같이 삭제 되는데 이 중에서 더티 페이지를 디스크에 기록하고 버퍼 캐시에서 지우는 것을 Lazy Write라고 한다.
메모리의 버퍼 캐시에 더티페이지 존재
--> Lazy Writer 프로세스가 주기적으로 버퍼 캐시에서 충분한 여유공간 있는지 체크
--> 여유 공간 확보위해 오래된 페이지들(클린 페이지 + 더티 페이지) 공간이 비워지게 되며 이 때 더티 페이지
lazy writer프로세스에 의해 디스크에 쓰여지고 공간 비워줌.
-- 더티 페이지 수 체크
SELECT db_name(database_id) AS 'Database',count(page_id) AS 'Dirty Pages'
FROM sys.dm_os_buffer_descriptors
WHERE is_modified =1
GROUP BY db_name(database_id)
ORDER BY count(page_id) DESC
주요 메모리 카운터 수치는 다음과 같이 차례대로 변한다.
Lazy Writes/sec 이 20 이상 지속
--> Page Life expectancy 값이 계속 저하됨
--> Disk I/O가 계속 늘어남(메모리에서 데이터 버퍼가 사라지고 디스크에서 메모리로 계속 신규 데이터를 퍼올리기 때문에)
--> CPU 사용률이 증가함
메모리 문제가 1차적 원인이었지만 Disk나 CPU의 성능이 하락하기 때문에 실제적으로 원인을 찾기 어려울 수 있다.
더티페이지를 디스크에 기록하는 것은 Lazy writer와 Checkpoint가 동일하지만 다음과 같은 차이가 있다.
a. 체크포인트 : 더티페이지가 디스크에 기록된 후에도 클린 페이지 상태로 버퍼 캐시에 계속 존재
b. Lazy Writer: 더티페이지를 디스크에 쓰는 것은 체크포인트와 동일하지만 이 후 버퍼 캐시에서 사라짐.
또한 SQL Server의 메모리를 OS에 반환하는 것도 임무 중 하나.
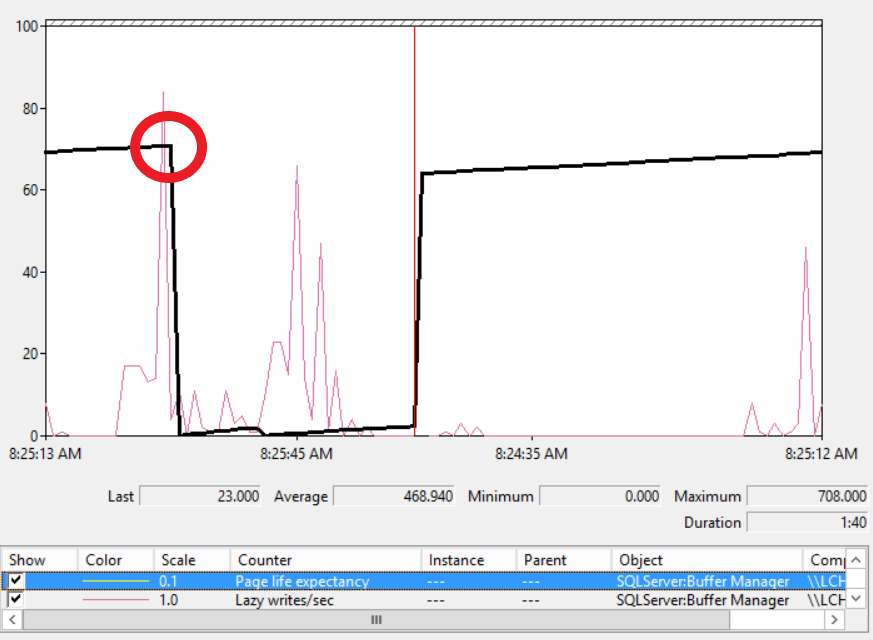
이 SQL Server는 현재 매우 좋지 않은 상황이다.
빨간색 원에서 PLE 수치가 0으로 떨어지는데 잘 보면 Lazy Write도 순간적으로 80까지 기록.
20이상이면 문제가 있다고 했는데 80까지 기록했으니 안 좋다. PLE 다운의 원인을 해결하면 Lazy Write도 정상화 될 것으로 판단 할 수 있다.
위의 상황을 쉽게 설명
a. 대량의 데이터 작업이 필요한 신규 쿼리가 실행이 된다.
b. SQL Server는 디스크에서 대량의 신규 데이터를 퍼 올리는데 메모리 버퍼 캐시의 빈 공간이 여의치 않다.
c. SQL Server는 버퍼 캐시에 입주하고 있는 페이지들 중에서 오래된 놈들 위주로 빨리 방빼라고 재촉을 한다.
d. 이 때 PLE 값이 급격히 하락
e. 클린 페이지들이야 동일 원본이 디스크에 있기 때문에 버퍼 캐시에서만 삭제하면 되지만 더티 페이지들은 checkpoint가 아직
안 왔기 때문에 일단 하드 디스크에 쓰는 작업을 먼저 수행해야 한다.
f. 이 때 디스크 쓰기 I/O가 급증하고 쓰기 작업은 cpu도 많이 소모하기 때문에 디스크, CPU 상황까지 안좋게 된다.
Lazy Write/sec 도 급증
g. 디스크 I/O는 메모리에 비해 속도가 많이 느리기 때문에 SQL Server는 재촉을 하지 디스크 I/O는 느리지 속이 타는 상황이 발생.
즉 병목현상이 발생
f. 겨우 겨우 디스크에 기록하게 되며 더티 페이지까지 버퍼 캐시에서 방 빼기 완료.
g. 신규 쿼리를 위한 새로운 데이터들이 버퍼 캐시에 올라오기 때문에 PLE 값도 서서히 오르기 시작
* Memory Grants Pending
SQL Server 메모리를 할당 받기 위해 대기하고 있는 그 시점의 sql 세션들 갯수. 이 값이 높으면 버퍼 메모리가 부족하다는 뜻이다. 정상 상태의 대부분 프로덕션 서버에서는 메모리 버퍼 캐시가 부족하지 않기 때문에 이 값이 계속 0으로 표시된다. 하지만 메모리 부족상태에가 되면 Lazy Write가 메모리를 비워주는 것을 기다려야 하는데 이때 수치가 상승하게 된다.
실시간으로 이 값을 판단하는 또 다른 방법은 sys.dm_exec_query_memory_grants(메모리 부여를 요청하고 메모리 부여 대기하고 있는 모든 쿼리 정보) DMV를 확인 해 보는 것이다. grant_time 컬럼값이 null이면 여전히 메모리 할당을 기다리고 있다는 표시. 쿼리들이 실행 대기하고 상태, 보통 "쿼리 타임아웃"을 트러블슈팅하기 위해 사용된다.
다음 시나리오 확인
a. sys.dm_os_memory_clerks, sys.dm_os_sys_info 를 통해 전체 시스템 메모리 상태 확인
b. sys.dm_os_memory_clerks의 type = 'MEMORYCLERK_SQLQERESERVATIONS' 에서 해당 쿼리 실행 메모리 예약을 확인
c. sys.dm_exec_query_memory_grants 대기하고 있는 쿼리 확인
SELECT *
FROM sys.dm_exec_query_memory_grants
WHERE grant_time is null
대부분의 대기 형식이 RESOURCE_SEMAPHORE
d. sys.dm_exec_query_plan 을 사용하여 tsql으로 메모리 부여를 사용하는 쿼리의 캐시 검색
-- retrieve every query plan from the plan cache
USE master;
GO
SELECT * FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle);
GO
e. sys.dm_exec_requests 를 사용하여 메모리 사용량이 많은 쿼리 자세히 검색
--Find top 5 queries by average CPU time
SELECT TOP 5 total_worker_time/execution_count AS [Avg CPU Time],
plan_handle, query_plan
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle)
ORDER BY total_worker_time/execution_count DESC;
GO
참고
sys.dm_exec_query_memory_grants
* Target Server Memory (KB) and Total Server Memory (KB)
Target Server Memory (KB) : SQL Server가 사용하길 원하는 동적 메모리의 양 Total Server Memory(KB) : 현재 SQL Server에 할당된 메모리 용량이며 보통의 전용 SQL Server라면 매우 높은게 일반적.
Total Server Memory (KB)가 Target Server Memory (KB)보다 심하게 낮다면 - SQL Server의 메모리 요구량이 낮거나 - max server memory 구성 값이 매우 낮게 세팅되어 있는 경우이다. - SQL Server가 시동중
5000 이상의 대량 여유 페이지들이 존재하는지 확인하여 낮은 메모리 요구상태인지 알 수 있다.
2.5 추가적인 메모리 모니터링 도구
상당히 많은 결과셋이 나오고 어떤 결과들은 NUMA 노드별로 표시된다. 이중 기본적인 2개의 결과만 살펴보자
DBCC MEMORYSTATUS
| Process/System Counts | Value |
|---|---|
| Available Physical Memory | 22234664960 |
| Available Virtual Memory | 22234661393228433080324960 |
| Available Paging File | 21294985216 |
| Working Set | 4612734976 |
| Percent of Committed Memory in WS | 100 |
| Page Faults | 434072664 |
| System physical memory high | 1 |
| System physical memory low | 0 |
| Process physical memory low | 0 |
| Process virtual memory low | 0 |
첫번째 결과를 해석하면 다음과 같다.
- Available Physical Memory : 현재 여유 용량은 약22GB (22234664960)
- System physical memory high : 1은 true. 시스템의 물리적 메모리 용량이 많다는 뜻
- Working Set : 메모리 작업집합은 4.5GB.
- Percent of Committed Memory in WS : 100%이니까 Working Set안에 Commit(할당)이 완전히 되었다는 뜻. 하지만 SQL Server는 WS이 아니고
별도의 Commit 메모리(Private memory)안에 버퍼풀을 유지한다. 그렇기 때문에 이 값은 의미 없음.
위 말도 맞는 완전히 맞는 말이 아니다. 이상하게도 Windows OS는 다른 용어를 같은 의미로 쓰는 경우가 많다.
시간되면 뒤에서 설명하겠다.
- Page Faults :
두번째 결과는 다음과 같다
| Memory Manager | KB |
|---|---|
| VM Reserved | 1380519060 |
| VM Committed | 5353596 |
| Locked Pages Allocated | 99504004 |
| Large Pages Allocated | 858112 |
| Emergency Memory | 1024 |
| Emergency Memory In Use | 16 |
| Target Committed | 104857600 |
| Current Committed | 104857600 |
| Pages Allocated | 88486280 |
| Pages Reserved | 3888 |
| Pages Free | 166416 |
| Pages In Use | 25631320 |
| Page Alloc Potential | 73983400 |
| NUMA Growth Phase | 2 |
| Last OOM Factor | 0 |
| Last OS Error | 0 |
두번째 결과를 해석하면
* Locked Pages Allocated : 이 서버는 Lock page in Memory 설정을 해 놓은 서버이고
현재 99GB가 Locked pages로 메모리상에 존재
* Target Committed : 104GB. 여기서 메모리 할당의 commit. 성능 카운터의 Target Server memory
* Current Committed : 104GB. 성능 카운터의 Total Server memory
* NUMA Growth Phasㅕ : NUMA 노드는 2개
더 자세한 것은 DBCC MEMORYSTATUS로 SQL Server 메모리 사용조사
동적 관리 객체(Dynamic Management Objects)
메모리 병목상황에서 가장 자구 사용되는 3개의 DMV과 인메모리 OLTP 메모리 사용할때 2개의 DMV
* sys.dm_os_buffer_descriptors
현재 SQL Server 버퍼 풀에 있는 모든 데이터 페이지에 대한 정보를 반환
-- 데이터별로 버퍼캐시 사용량
SELECT *
, DirtyPageCount * 8 / 1024 AS DirtyPage_MB
, CleanPageCount * 8 / 1024 AS CleanPage_MB
, (DirtyPageCount * 8 / 1024) + (CleanPageCount * 8 / 1024) AS Total_MB
FROM
(
SELECT
CASE
WHEN database_id = 32767 THEN N'Resource Database'
ELSE DB_NAME(database_id)
END AS DBName
, numa_node
, SUM(CASE WHEN (is_modified = 1) THEN 1 ELSE 0 END) AS DirtyPageCount
, SUM(CASE WHEN (is_modified = 1) THEN 0 ELSE 1 END) AS CleanPageCount
FROM sys.dm_os_buffer_descriptors
GROUP BY database_id, numa_node
) T
ORDER BY numa_node, DBName
GO
DBNamed numa_node DirtyPageCount CleanPageCount DirtyPage_MB CleanPage_MB Total_MB
---------------- --------- -------------- -------------- ------------ ------------ ---------
APPLE 0 0 1353 0 10 10
GREEN_FRUIT 0 0 1654 0 12 12
master 0 0 258 0 2 2
model 0 0 41 0 0 0
msdb 0 0 319 0 2 2
PEPPER 0 0 38810 0 303 303
ROSE 0 0 2370 0 18 18
tempdb 0 0 448865 21 3506 3527
TOMATO 0 0 1233 0 9 9
APPLE 1 0 381 0 9 9
GREEN_FRUIT 1 0 2370 0 18 18
master 1 0 12 255 0 255
model 1 0 24 0 0 0
msdb 1 0 6 0 0 0
PEPPER 1 0 102 13 0 0
ROSE 1 0 29472 0 230 230
tempdb 1 5737 21118 44 164 208
TOMATO 1 14 23 0 0 0
보면 NUMA 노드 0번과 1번의 버퍼캐시량이 틀리기 때문에 실제 디테일하게 NUMA 노드별로 확인하는게
정답이지만 대부분 비슷하기 때문에 평균 값으로 보는 경우가 대부분.
-- 현재 DB의 오브젝트별 버퍼 캐시 사용량
SELECT COUNT(*)AS cached_pages_count
,name ,index_id
FROM sys.dm_os_buffer_descriptors AS bd
INNER JOIN
(
SELECT object_name(object_id) AS name, index_id, allocation_unit_id
FROM sys.allocation_units au
INNER JOIN sys.partitions AS p ON au.container_id = p.hobt_id AND (au.type = 1 OR au.type = 3)
UNION ALL
SELECT object_name(object_id) AS name, index_id, allocation_unit_id
FROM sys.allocation_units au
INNER JOIN sys.partitions AS p ON au.container_id = p.partition_id AND au.type = 2
) obj ON bd.allocation_unit_id = obj.allocation_unit_id
WHERE database_id = DB_ID()
GROUP BY name, index_id
ORDER BY cached_pages_count DESC;
cached_pages_count name index_id
------------------ ---------------------- -----------
1981787 AAAABBBCCCCC 1
1126135 TTADBAC 1
569121 OK_TABLE 1
433561 OK_TABLE 2
* sys.dm_os_memory_brokers
SQL Server의 대부분 메모리는 버퍼 캐시 부분이고 많은 프로세스들이 SQL Server안의 메모리를 소비한다. 이런 프로세스들이 자신들이 소비하는 메모리 할당 정보를 이 DMV를 통해서 노출한다. 메모리 병목 상황에서 어떤 프로세스들이 버퍼 캐시에서 가져오고 날리는지 리소스 소비 정보를 알수 있다.
SELECT *
FROM sys.dm_os_memory_brokers
pool_id memory_broker_type allocations_kb allocations_kb_per_sec predicted_allocations_kb target_allocations_kb
------- ---------------------------------- -------------- ---------------------- ------------------------ ---------------------
1 MEMORYBROKER_FOR_CACHE 542560 -4502 542560 55034560
1 MEMORYBROKER_FOR_STEAL 206328 0 206328 54698328
1 MEMORYBROKER_FOR_RESERVE 0 0 0 54492000
1 MEMORYBROKER_FOR_COMMITTED 16204904 0 16204904 70696904
1 MEMORYBROKER_FOR_HASHED_DATA_PAGES 0 0 0 54492000
1 MEMORYBROKER_FOR_XTP 2856 0 2856 54494856
2 MEMORYBROKER_FOR_CACHE 8594736 66 8595000 63087000
2 MEMORYBROKER_FOR_STEAL 52096 -326 52096 54544096
2 MEMORYBROKER_FOR_RESERVE 37072 416 19518976 74010976
2 MEMORYBROKER_FOR_HASHED_DATA_PAGES 0 0 0 54492000
2 MEMORYBROKER_FOR_XTP 0 0 0 54492000
자세한 것은 설명서를 찾아보고 중요한 내용만 설명한다
* pool_id : SQL Server의 기본 리소스 관리자의 풀인 (default:0, internal:1) 표시. 리소스 풀을 추가하면 여기서도 표시됨
* memory_broker_type : 3개의 브로커인
MEMORYBROKER_FOR_CACHE : 캐시된 오브젝트 메모리 양. (버퍼 풀 캐시 아님)
MEMORYBROKER_FOR_STEAL : 버퍼 풀에서 컴파일에 사용하기 위해 뺏어온 메모리
MEMORYBROKER_FOR_RESERVE : 쿼리 실행을 위해 예약된 메모리
* allocations_kb : 현재 할당된 메모리 양(KB)
모든 메모리 브로커의 정보도 없고 이 메모리가 실제 물리적 메모리와 아무리 검증해 봐도 틀리기 때문에 내능력으로는 이걸 이용할 수 없다
* sys.dm_os_memory_clerks
메모리 클럭은 SQL Server안의 메모리를 할당하는 프로세스들이다. 내부 메모리 할당 문제같은 경우를 파악할 수 있다.
SELECT top 10 [type], memory_node_id, sum(pages_kb) pages_kb
FROM sys.dm_os_memory_clerks
GROUP BY [type], memory_node_id
order BY pages_kb desc
type memory_node_id pages_kb
------------------------------ -------------- --------------------
MEMORYCLERK_SQLBUFFERPOOL 0 58531776
MEMORYCLERK_SQLBUFFERPOOL 1 23224056
CACHESTORE_SQLCP 0 4300568
OBJECTSTORE_LOCK_MANAGER 0 634856
OBJECTSTORE_LOCK_MANAGER 1 620576
OBJECTSTORE_XACT_CACHE 0 397624
USERSTORE_SCHEMAMGR 0 157296
CACHESTORE_OBJCP 0 131712
MEMORYCLERK_SQLQERESERVATIONS 1 66760
MEMORYCLERK_SQLGENERAL 0 66640
이 수치만 봐도 이서버의 대략적인 상황을 유추할 수 있다.
* MEMORYCLERK_SQLBUFFERPOOL : max server memory가 110GB인 서버이니 MEMORYCLERK_SQLBUFFERPOOL들 합치면 90GB 정도되고
나머지 20GB가 다른 용도로 쓰인다
* CACHESTORE_SQLCP : 4.3GB나 사용. prepared나 ad-hoc 쿼리의 컴파일된 계획의 캐시니까
이 서버에는 다양한 패턴의 많은 임시쿼리들이 들어 온다는 것을 알수 있다
* CACHESTORE_OBJCP : sp, 함수등의 컴파일된 실행계획
* OBJECTSTORE_LOCK_MANAGER : lock이 소비하는 메모리인데 너무 많을 경우 심각한 블로킹 문제가 발생할 수 있다.
실제 이서버는 블로킹 문제가 매우 심각하다.
또한 rowlock 힌트를 사용한 대량의 테이블 삭제 배치 작업이 빈번하게 수행된다.
이 배치 개발자는 오라클에 익숙한 사람일 것이며 그 방식대로 해결하려 하는데
하지만 MSSQL에서는 그로 인하여 적절한 lock escalation이 발생하지 않는 등의 심각한 문제가
있으며 실제 이 배치 작업도 큰 성능 저하를 일으키고 있다.
* OBJECTSTORE_XACT_CACHE : 트랜잭션 정보 캐시하는데 사용. 용량도 400MB이니 크다
이 서버는 대량 데이터 삭제/갱신 배치작업이 매우 빈번하고 그로 인해 Batchreqest/sec 보다
TPS가 높은 상황이다. 이런 문제로 인해 매우 높은 수치가 발생함을 알 수 있다.
* USERSTORE_SCHEMAMGR : 다양한 유형의 오브젝트 메타 데이터 정보 캐시. 150MB로 높다.
실제로 이 서버는 임시 테이블, 임시 테이블 변수, 작업 테이블들에 대량의 임시 데이터를
담아 사용한다. 따라서 tempdb 사용량도 매우 높으며 버퍼캐시의 데이터 페이지수를 세어보면
tempdb쪽에서 높은 수치.
즉 임시 오브젝트를 수행하는 로직들을 찾아 개선할 필요가 있음을 알 수 있다.
* sys.dm_os_ring_buffers
이 DMV는 온라인 설명서에 문서화되어 있지 않으므로 변경되거나 제거 될 수 있습니다. SQL Server 2008R2와 SQL Server 2012 사이에서 변경되었습니다. 일반적으로 실행하는 쿼리는 SQL Server 2014에서도 작동하는 것처럼 보이지만 믿을 수 없습니다. 이 DMV는 XML로 출력됩니다. 일반적으로 출력을 눈으로 읽을 수 있지만 링 버퍼에서 정말 정교한 읽기를 얻으려면 XQuery를 구현해야 할 수도 있습니다.
링 버퍼는 알림에 대한 기록 된 응답에 지나지 않습니다. 링 버퍼는이 DMV 내에 보관되며 sys.dm_os_ring_buffers에 액세스하면 메모리 내에서 변경되는 사항을 볼 수 있습니다. 아래 표는 메모리와 관련된 기본 링 버퍼를 설명합니다.
Ring Buffer Ring_buffer_type 설명
----------------- ------------------------------ -------------------
Resource Monitor RING_BUFFER_RESOURCE_MONITOR 메모리 할당이 변하는 상황 기록. 외부 메모리 압박을 식별할때 유용
Out Of Memory RING_BUFFER_OOM 메모리 부족상황에서 할당 실패타입이 기록됨.
Memory Broker RING_BUFFER_MEMORY_BROKER 내부적으로 메모리가 모자르면 낮은 메모리 알림으로 안해 강제적으로 버퍼메모리를
비우라고 프로세스들에게 통지된다. 이런 통지 기록이 저장되기에 내부적 메모리 압박이
발생할때 알 수 있는 유용한 정보
Buffer Pool RING_BUFFER_BUFFER_POOL 버퍼 풀 자체적으로 메모리 부족상황을 기록 통지. 일반적인 메모리압박 표시
SELECT *
FROM sys.dm_os_ring_buffers
WHERE ring_buffer_type = 'RING_BUFFER_MEMORY_BROKER'
order by timestamp desc
<Record id = "60355" type ="RING_BUFFER_MEMORY_BROKER" time ="16919211856">
<MemoryBroker>
<DeltaTime>120</DeltaTime>
<Pool>2</Pool>
<Broker>MEMORYBROKER_FOR_XTP</Broker>
<Notification>GROW</Notification>
<MemoryRatio>100</MemoryRatio>
<NewTarget>4434919</NewTarget>
<Overall>10506240</Overall>
<Rate>0</Rate>
<CurrentlyPredicted>0</CurrentlyPredicted>
<CurrentlyAllocated>0</CurrentlyAllocated>
<PreviouslyAllocated>0</PreviouslyAllocated>
</MemoryBroker>
</Record>
MEMORYBROKER_FOR_XTP 브로커가 2번째 풀(리소스 관리자의 2번풀인 internal)에서 비우라고 기록됨
* sys.dm_db_xtp_table_memory_stats
인메모리 OLTP상에서 할당받은 테이블, 인덱스의 메모리 정보
* sys.dm_xtp_system_memory_consumers
이 DMV는 인 메모리 엔진의 내부를 관리하는 데 사용되는 시스템 구조를 보여줍니다. 일반적으로 처리해야하는 문제는 아니지만 메모리 문제를 해결할 때 시스템 내에서 발생하는 문제를 직접 처리하는지 아니면 메모리에로드 한 데이터의 양만 처리하는지 이해하는 것이 좋습니다. 여기서 찾고자하는 주요 측정은 각 관리 구조에 대해 표시된 할당 및 사용 된 바이트입니다.
2.6 메모리 병목 해결 방법
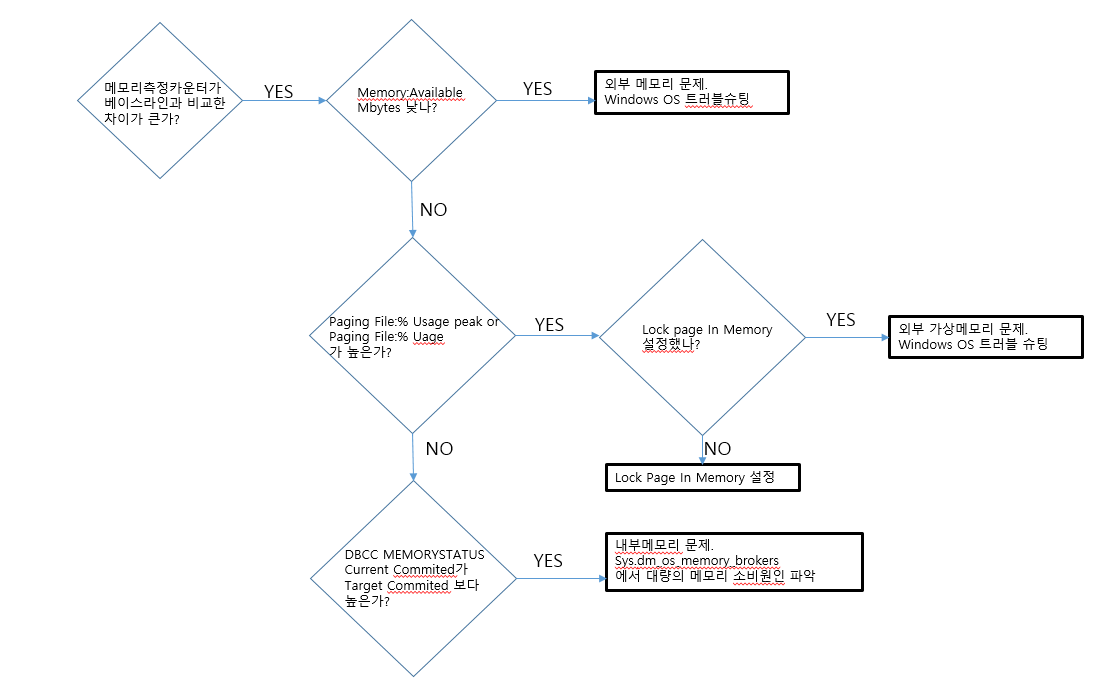
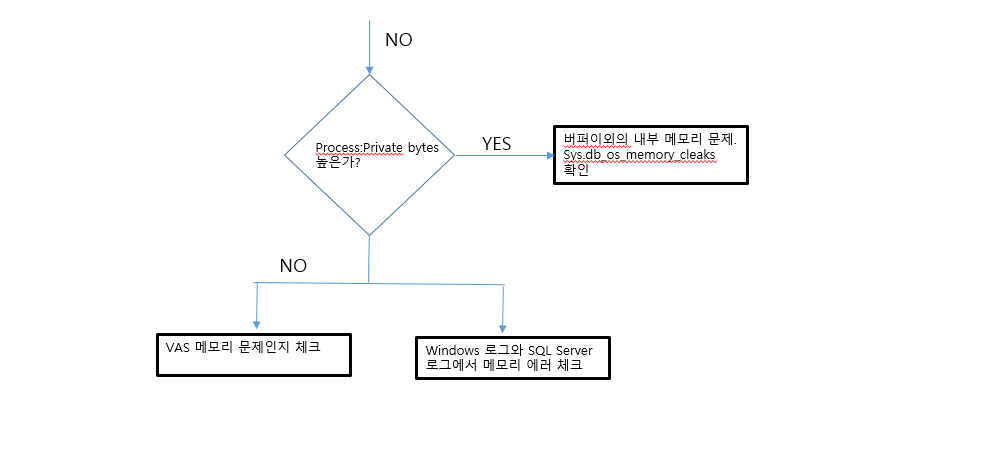
메모리 병목 해결을 위한 몇가지 공통적인 해결책
* 어플리케이션 워크로드 최적화
* SQL Server에 메모리 할당량 추가
* In-Memory 테이블을 표준 저장장치로 돌리기
* 시스템 메모리 추가
* 데이터 압축
* 조각화 해결
어플리케이션 워크로드 최적화
어플리케이션 워크로드 최적화(쿼리 튜닝 같은)는 대부분의 경우 가장 좋은 해결방법이다. 하지만 가장 복잡하고 어렵기 때문에 보통 최후에 선택된다. 메모리 집약적인 쿼리를 식별하기 위해서는 확장이벤트(XE)를 이용해서 reads 수가 많은 것을 추려내야 한다. sys.dm_exec_query_stats DMV의 도움을 받자. 이 DMV는 빠르고 쉽지만 캐시에 근거하는 결과(prepared 쿼리)이기 때문에 파라메터 값같은 것들이 확장이벤트를 사용하는 것만큼 정확하지는 않을 수 있다.
SQL Server에 메모리 할당량 추가
SQL Server의 max server memory를 올려주면 당장은 매우 큰 효과를 얻을 수있다.
인메모리 OLTP저장소를 사용한다면 SQL Server에서 메모리를 땡겨갈 수 있기 때문에 적절한 리소스 풀 수치를 조절해 주어야 한다.
In-Memory 테이블을 표준 저장장치로 돌리기
2014에서 처음 소개된 인메모리 테이블은 성능 향상을 위해 저장 공간을 디스크에서 메모리로 옮겨 위치하게 된다. 하지만 모든 테이블이나 워크로드가 메모리에 있는게 좋은것은 아니기 때문에 다시 디스크로 내리면 될 때가 있다.
시스템 메모리 추가
시스템에 메모리를 추가하고 sys.dm_exec_query_memory_grants 로 메모리 집약적 쿼리들을 모니터링.
데이터 압축
데이터 압축은 일반적으로 매우 좋은 해결 방법이다. 메모리에서도 압축된 형태로 올라 오기 때문에 더 적은 메모리 시스템에서도 메모리 사용률을 올릴 수 있다. 물론 CPU의 비용이 증가하나 얻는 이점에 비해 감당할 만 하다.
디스크 조각화 해결
저장소의 조각화 상태는 성능 이슈가 발생한다. 만약 디스크의 조각화가 심한 경우라면 메모리로 올리는 시간도 더 걸리게 된다.
요약
메모리 드뎌 끝. 모든 쿼리 검증하고 내용 추가/수정하고 반복하다 보니 1장에 1달 넘게 걸림. 가볍게 생각했는데 매우 힘든 작업임. =======